
漢王PDF OCR
v8.1.4.16官方正式版- 軟件大小:23.72 MB
- 軟件語言:簡體中文
- 更新時間:2024-01-12
- 軟件類型:國產軟件 / 轉換翻譯
- 運行環境:winall/win7/win10/win11
- 軟件授權:免費軟件
- 官方主頁:http://www.562682.com
- 軟件等級 :
- 軟件廠商:暫無
- 介紹說明
- 下載地址
- 精品推薦
- 相關軟件
- 網友評論
 漢王 PDF OCR官方版是漢王OCR 6.0 和尚書七號的升級版,新增PDF文件的處理功能,可以把PDF文件(包括文本型和圖片型)轉化為可編輯的各種文檔,如(PDFTOWORD)或(PDFTOTXT)。漢王 PDF OCR官方版現已全面升級,并且對個人用戶免費,無功能限制。
漢王 PDF OCR官方版是漢王OCR 6.0 和尚書七號的升級版,新增PDF文件的處理功能,可以把PDF文件(包括文本型和圖片型)轉化為可編輯的各種文檔,如(PDFTOWORD)或(PDFTOTXT)。漢王 PDF OCR官方版現已全面升級,并且對個人用戶免費,無功能限制。
快捷鍵速記
掃描文件: 按下“Ctrl+N”調出掃描程序,掃描圖像文件。
打開文件: 按下“Ctrl+O”打開圖像文件,追加圖像文件。
保存圖像: 按下“Ctrl+S”鍵保存圖像。
圖像反白: 按下“Ctrl+I”將圖像反白。
自動傾斜校正: 按下“Ctrl+D”進行自動傾斜校正。
手動傾斜校正: 按下“Ctrl+M”進行手動傾斜校正。
版面分析: 按下“F5”鍵,對選中的文件進行版面分析。
取消版面分析: 按下“Ctrl+Del”鍵,取消當前頁的版面分析。
漢王PDF OCR軟件特色
1.圖像輸入、圖像前處理、預識別。
2.圖像輸入
漢王PDF OCR官方版對于不同的圖像格式,有著不同的存儲格式,不同的壓縮方式,目前有OpenCV、CxImage等開源項目。
3.預處理
漢王ocr文字識別軟件功能主要包括二值化,噪聲去除,傾斜較正等。
4.二值化
對攝像頭拍攝的圖片,大多數是彩色圖像,彩色圖像所含信息量巨大,對于圖片的內容,可以簡單的分為前景與背景,為了讓計算機更快的、更好地識別文字,我們需要先對彩色圖進行處理,使圖片只前景信息與背景信息,可以簡單的定義前景信息為黑色,背景信息為白色,這就是二值化圖。
5.噪聲去除
對于不同的文檔,對噪聲的定義可以不同,根據噪聲的特征進行去燥,就叫做噪聲去除。
6.傾斜校正
由于一般用戶,在拍照文檔時,都比較隨意,因此拍照出來的圖片不可避免的產生傾斜,這就需要文字識別軟件進行較正。
7.版面分析
漢王ocr文字識別軟件可以將文檔圖片分段落,分行的過程就叫做版面分析,由于實際文檔的多樣性,復雜性,因此,目前還沒有一個固定的,最優的切割模型。
8.字符切割
由于拍照條件的限制,經常造成字符粘連,斷筆,因此極大限制了識別系統的性能。
9.字符識別
這一研究已經是很早的事情了,比較早有模板匹配,后來以特征提取為主,由于文字的位移,筆畫的粗細,斷筆,粘連,旋轉等因素的影響,極大影響特征的提取的難度。
10.版面還原
人們希望識別后的文字,仍然像原文檔圖片那樣排列著,段落不變,位置不變,順序不變地輸出到Word文檔、PDF文檔等,這一過程就叫做版面還原。
11.后處理、校對
漢王PDF OCR根據特定的語言上下文的關系,對識別結果進行校正,就是后處理。
使用方法
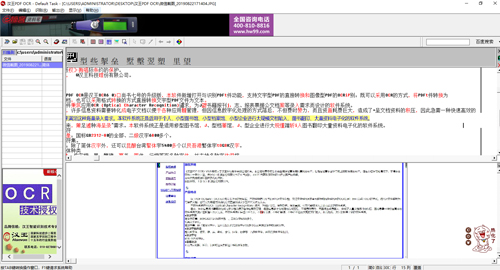
文件管理區:對文件進行管理和整理。
1.打開文件:選擇“文件”菜單,選擇打開圖像文件的路徑,圖像文件便顯示在管理區用鼠標可將圖像文件拖拽到管理區,也可將打開的圖像頁復制、粘貼到管理區。
2.刪除文件:按鍵盤上的“Delete”鍵將文件刪除。
3.調整文件:選中一個文件或按住Ctrl可以選擇多個文件,把文件拖放到要調整的位置。
4.文件格式:本系統支持TIF、BMP、PDF,彩色灰度圖還支持JPG格式。
5.文件語言:本系統支持中文簡體、英文、簡繁體混排方式、以及中英文混排方式。
6.圖像文件重命名:選中文件,點擊文件菜單選擇可保存成TIF、BMP、JPG文件(說明:本系統不支持批量圖像文件的改名)。
7.圖像文件保存路徑:在 中可以設置獲取圖像文件的路徑、名稱、格式。如該路徑不存在,系統會提示是否創建該路徑;如果要選擇已存在的某個路徑,可以點擊“掃描到”按鈕,彈出選擇路徑對話框,選擇需要保存圖像的路徑。
中可以設置獲取圖像文件的路徑、名稱、格式。如該路徑不存在,系統會提示是否創建該路徑;如果要選擇已存在的某個路徑,可以點擊“掃描到”按鈕,彈出選擇路徑對話框,選擇需要保存圖像的路徑。
侯選字區:修改識別結果時,可以選擇侯選區的字直接修改當前字。
識別結果區:顯示當前圖像文件的識別結果。
原圖像區:顯示當前正處理的圖像。
搜索區:百度、Google搜索。
FAQ
如何使用?
1.運行漢王PDF OCR軟件

2.點擊左上角【文件】-【打開圖像】,選擇一副包含文字的圖片。
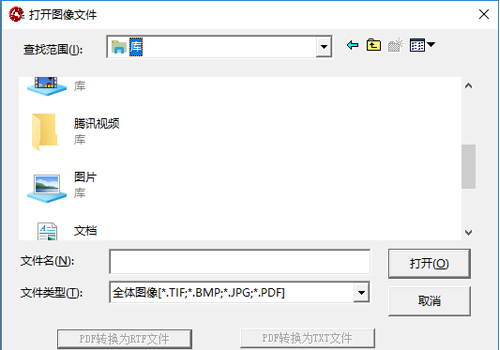
3.點擊【識別】-【開始識別】。
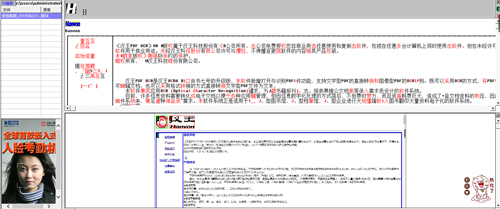
4.漢王ocr文字識別軟件會識別出圖片上的文字,可以對一些識別錯誤的字進行手動修改。
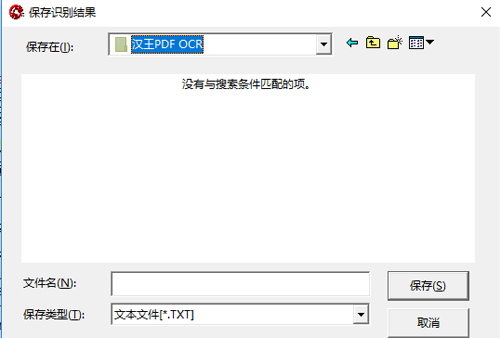
5.修改完成后點擊【輸出】-【到指定格式】,保存識別出來的文本。
用戶評論
轉換:
軟件很好用,免費,簡單實用。
大海全是水:
軟件很實用,使用起來也很方便。
悟空:
還可以將圖片轉換為PDF,功能還挺全的。
小編寄語
小知識:漢王 PDF OCR文字識別技術
光學字符識別(英語:Optical Character Recognition, OCR)是指對文本資料的圖像文件進行分析識別處理,獲取文字及版面信息的過程。
OCR的概念是在1929年由德國科學家Tausheck最先提出來,并申請了專利。后來美國科學家Handel也提出了利用技術對文字進行識別的想法。國內最早的OCR商業應用是由中國科學家王慶人教授在南開大學開發出來的,并在美國市場投入商業使用。
下載地址
- Pc版
漢王PDF OCR v8.1.4.16官方正式版
相關軟件
本類排名
- 1FoxPDF Works to PDF Converterv3.0官方正式版
- 2VeryPDF Document Converterv8.0官方正式版
- 3VeryPDF Scan to Word OCR Converterv3.10官方正式版
- 4PDF2TIFFv1.0.2官方正式版
- 5WORD翻譯軟件v1.3官方正式版
- 6Vbs To Exe x32v3.0.9官方正式版
- 7csv2vCardv1.0官方正式版
- 8Coolmuster Word to PDF Converterv2.1.7官方正式版
- 9繁體簡體字幕轉換工具v1.0官方正式版
- 10Adept Translator Prov5.6.0官方正式版




















網友評論