Python實現SQL Server數據庫實現對象同步輕量級
時間:2024-02-05 11:03作者:下載吧人氣:35
緣由
日常工作中經常遇到類似的問題:把某個服務器上的某些指定的表同步到另外一臺服務器。
類似需求用SSIS或者其他ETL工作很容易實現,比如用SSIS的話,就會會存在相當一部分反復的手工操作。
建源的數據庫信息,目標的數據庫信息,如果是多個表,需要一個一個地拉source和target,然后一個一個地mapping,然后運行實現數據同步。
然后很可能,這個workflow使用也就這么一次,就壽終正寢了,卻一樣要浪費時間去做這個ETL。
快速數據同步實現
于是在想,可不可能快速實現類似需求,盡最大程度減少重復的手工操作?類似基于命令行的方式,簡單快捷,不需要太多的手動操作。
于是就有了本文,基于Python(目的是順便熟悉一下Python的語法),快速實現SQL Server的數據庫之間的數據同步操作,后面又稍微擴展了一下,可以實現不同服務器的數據庫之間的表結構,表對應的數據,存儲過程,函數,用戶自定義類型表(user define table type)的同步
目前支持在兩個SQL Server數據源之間:每次同步一張或者多張表/存儲過程,也可以同步整個數據庫的所有表/存儲過程(以及表/存儲過程依賴的其他數據庫對象)。
支持sqlserver2012以上版本
需要考慮到一些基本的校驗問題:在源服務器上,需要同步的對象是否存在,或者輸入的對象是否存在于源服務器的數據庫里。
在目標服務器上,對于表的同步:
1,表的存在依賴于schema,需要考慮到表的schema是否存在,如果不存在先在target庫上創建表對應的schema
2,target表中是否有數據?如果有數據,是否以覆蓋的方式執行
對于存儲過程的同步:
1,類似于表,需要考慮存儲過程的schema是否存在,如果不存在先在target庫上創建表對應的schema
2,類似于表,arget數據庫中是否已經存在對應的存儲過程,是否以覆蓋的方式執行
3,存儲過程可能依賴于b表,某些函數,用戶自定義表變量等等,同步存儲過程的時候需要先同步依賴的對象,這一點比較復雜,實現過程中遇到在很多很多的坑
可能存在對象A依賴于對象B,對象B依賴于對象C……,這里有點遞歸的意思
這一點導致了重構大量的代碼,一開始都是直來直去的同步,無法實現這個邏輯,切實體會到代碼的“單一職責”原則
參數說明
參數說明如下,大的包括四類:
1,源服務器信息 (服務器地址,實例名,數據庫名稱,用戶名,密碼),沒有用戶名密碼的情況下,使用windows身份認證模式
2,目標服務器信息(服務器地址,實例名,數據庫名稱,用戶名,密碼),沒有用戶名密碼的情況下,使用windows身份認證模式
3,同步的對象類型以及對象
4,同步的對象在目標服務器上存在的情況下,是否強制覆蓋
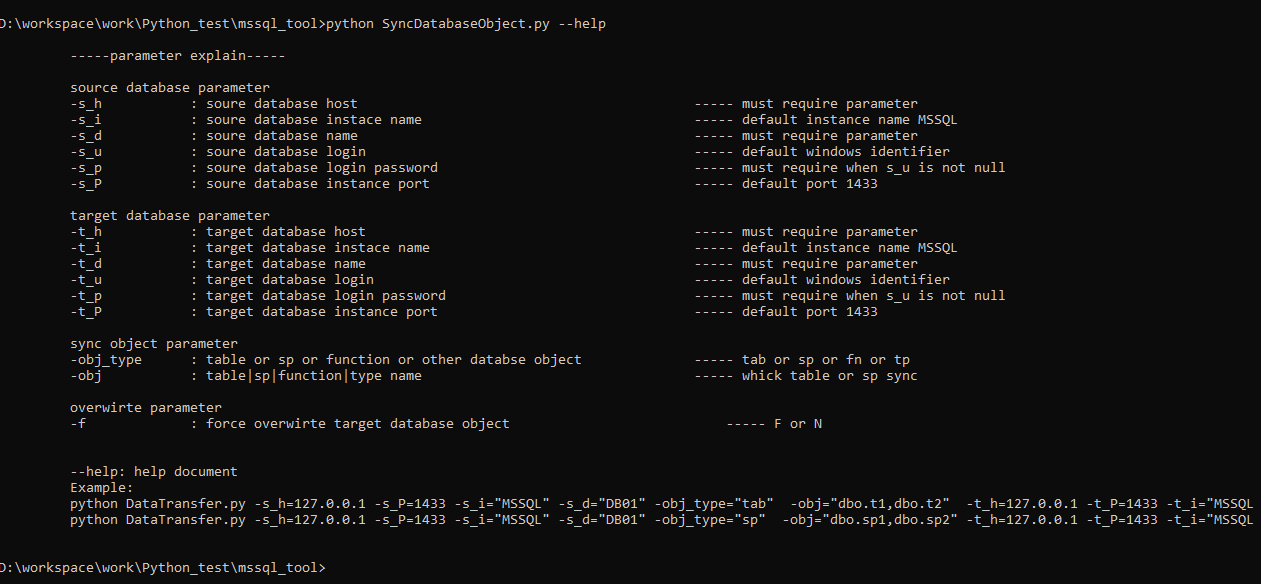
其實在同步數據的時候,也可以把需要同步的行數提取出來做參數,比較簡單,這里暫時沒有做。
比如需要快速搭建一個測試環境,需要同步所有的表結構和每個表的一部分數據即可。
表以及數據同步
表同步的原理是,創建目標表,遍歷源數據的表,生成insert into values(***),(***),(***)格式的sql,然后插入目標數據庫,這里大概步驟如下:
1,表依賴于schema,所以同步表之前先同步schema
2,強制覆蓋的情況下,會drop掉目標表(如果存在的話),防止目標表與源表結構不一致,非強制覆蓋的情況下,如果字段不一致,則拋出異常
3,同步表結構,包括字段,索引,約束等等,但是無法支持外鍵,刻意去掉了外鍵,想想為什么?因吹斯汀。
4,需要篩選出來非計算列字段,insert語句只能是非計算列字段(又導致重構了部分代碼)
5,轉義處理,在拼湊SQL的時候,需要進行轉義處理,否則會導致SQL語句錯誤,目前處理了字符串中的’字符,二進制字段,時間字段的轉義處理(最容易發生問題的地方)
6,鑒于insert into values(***),(***),(***)語法上允許的最大值是1000,因此每生成1000條數據,就同步一次
7,自增列的identity_insert 標識打開與關閉處理
使用如下參數,同步源數據庫的三張表到目標數據庫,因為這里是在本機命名實例下測試,因此實例名和端口號輸入
執行同步的效果
說明:
1,如果輸入obj_type=”tab” 且-obj=為None的情況下,會同步源數據庫中的所有表。
2,這個效率取決于機器性能和網絡傳輸,本機測試的話,每秒中可以提交3到4次,也就是每秒鐘可以提交3000~4000行左右的數據。
已知的問題:
1,當表的索引為filter index的時候,無法生成包含where條件的索引創建語句,那個看起來蛋疼的表結構導出語句,暫時沒時間改它。
2,暫時不支持其他少用的類型字段,比如地理空間字段什么的。
存儲過程對象的同步
存儲過程同步的原理是,在源數據庫上生成創建存儲過程的語句,然后寫入目標庫,這里大概步驟如下:
1,存儲過程依賴于schema,所以同步存儲過程之前先同步schema(同表)
2,同步的過程會檢查依賴對象,如果依賴其他對象,暫停當前對象同步,先同步依賴對象
3,重復第二步驟,直至完成
4,對于存儲過程的同步,如果是強制覆蓋的話,強制覆蓋僅僅對存儲過程自己生效(刪除&重建),對依賴對象并不生效,如果依賴對象不存在,就創建,否則不做任何事情
使用如下參數,同步源數據庫的兩個存儲過程到目標數據庫,因為這里是在本機命名實例下測試,因此實例名和端口號輸入
說明:測試要同步的存儲過程之一為[dbo].[sp_test01],它依賴于其他兩個對象:dbo.table01和dbo.fn_test01()
create proc [dbo].[sp_test01] as begin set no count on; delete from dbo.table01 where id = 1000 select dbo.fn_test01() end
相關推薦
- 數據庫開發知識:SpringBoot 開發MongoDB?Aggregations用法詳解
- 教你Linux 如何定時備份postgresql 數據庫
- SQL?Server數據庫備份和恢復數據庫的全過程
- 教你如何解決mongoDB數據庫添加賬號的問題處理
- 數據庫開發知識:SpringBoot?怎么集成MongoDB實現文件上傳功能
- mongoDB數據庫基礎 之 索引快速入門
- MongoDB 數據庫基礎 之 mongodb的備份與恢復
- postgresql數據庫基礎 特殊字符 ~*符號的含義及用法
- MongoDB數據庫集合的增刪改查管理詳細教程
- SQL基礎:SQLServer2019 數據庫的基本使用之圖形化界面操作的實現
相關下載
熱門閱覽
- 1SQL開發知識:MyBatis SQL xml處理小于號與大于號正確的格式
- 2SQL異常:教你sqlserver連接錯誤之SQL評估期已過的問題解決方法
- 3SQL基礎:SQLServer2019 數據庫的基本使用之圖形化界面操作的實現
- 4一文教你SQL Server2012的數據庫備份和還原的教程
- 5SQL報錯:由于系統錯誤 126 (SQL Server),指定驅動程序無法加載問題的處理
- 6SQL開發知識:SQL中Truncate的用法
- 7SQL開發知識:SQL Server執行動態SQL的正確方法
- 8數據庫恢復之 delete誤刪數據使用SCN號恢復的詳細方希
- 9SQL基礎:SQL?Server的全文搜索功能
- 10SQL開發知識:SQL Server數據庫查找表名或列名中包含空格的表和列
- 11Navicat 如何連接SQLServer數據庫詳細步驟截圖
- 12PL/SQL Developer過期的解決方法
最新排行
- 1SQL開發知識:SQL注入工具
- 2SQL開發知識:SQL 在自增列插入指定數據的操作方法
- 3Sql Server2012數據庫使用IP登錄服務器的配置教程
- 4SQL開發知識:Navicat導出.sql文件方法
- 5SQL開發知識:SQL Server表和索引存儲結構
- 6SQL開發知識:Sql注入原理簡介
- 7SQL開發知識:SQL Server Management Studio(SSMS)復制數據庫的方法
- 8SQL開發知識:SQL Server執行動態SQL的正確方法
- 9SQL開發知識:SQL Server Parameter Sniffing及其改進方法
- 10SQL開發知識:sql server2008調試存儲過程的步驟
- 11SQL開發知識:SQL Server非動態 SQL語句來對動態查詢進行執行
- 12一文帶你詳解SQL Server 2016數據庫快照代理過程

網友評論