MongoDB學習以及集群搭建的實踐全紀錄
時間:2024-03-04 00:33作者:下載吧人氣:24
前言
最近一些變動,有一個老項目交由我們組負責維護,碰到這樣的事情我的內心是崩潰的,但還得強顏歡笑,拍著胸脯說沒問題。更悲哀的是,該項目中還使用了mongo,還是自己搭建的,沒有交由DBA統一管理,無奈,只能趕鴨子上架,自己學習mongo了。
為什么使用集群架構?
主從:故障轉移:無法實現,如果主機宕機,需要關閉slave并且按照master模式啟動。無法解決單點故障 無法autofailover 不可以自動主從的切換
為了解決主從的問題,MongoDB3.0之后出現副本集,副本集解決了故障轉移的問題,但是一個副本集中的數據是相同的,無法做到海量數據的存儲。所以就需要一個架構去解決這個問題。也就是分片式集群。
一個健壯的簡單的MongoDB集群的搭建需要十個服務進程(分開搭建需要十臺服務器),這里在一臺虛擬機上進行搭建。
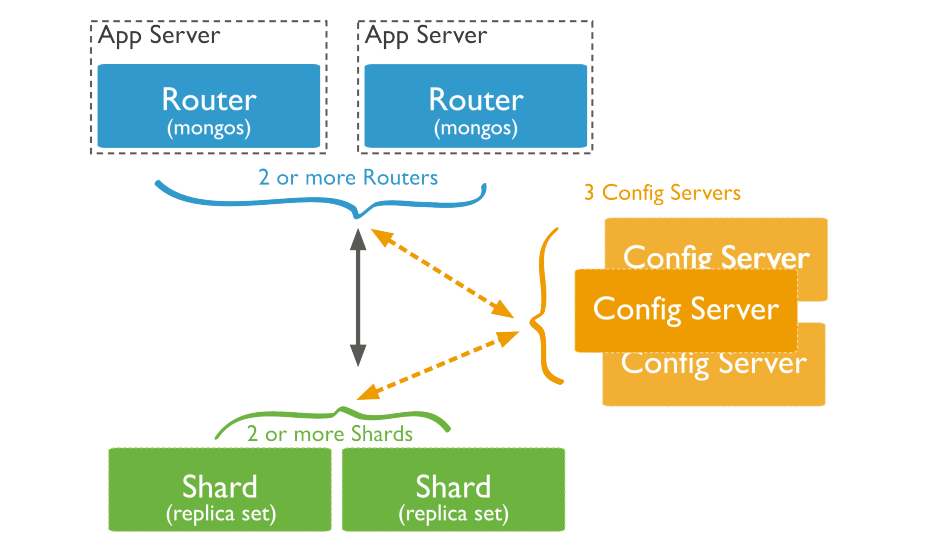
關于MongoDB
mongodb的集群搭建方式主要有三種,主從模式,Replica set模式,sharding模式, 三種模式各有優劣,適用于不同的場合,屬Replica set應用最為廣泛,主從模式現在用的較少,sharding模式最為完備,但配置維護較為復雜。
而目前接手過來的項目所用的就是Replica set,所以也就主要了解了這個模式。官網介紹可以點擊這里
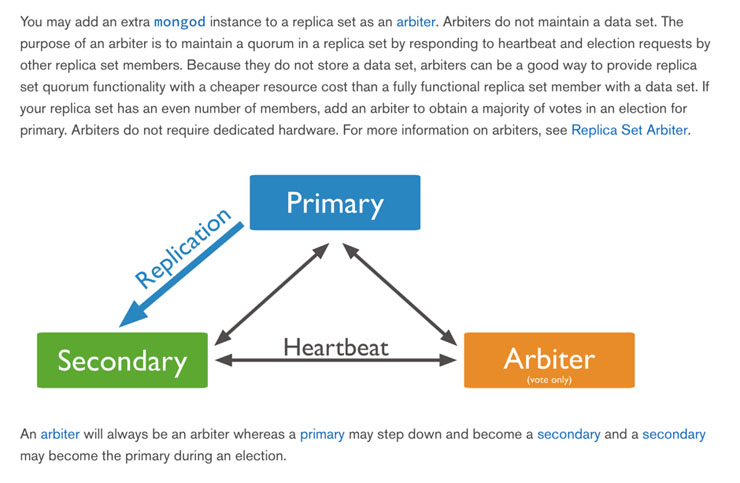
其中Replica Set模式中三類角色有必要知道下:
主節點[Primary]
接收所有的寫請求,然后把修改同步到所有Secondary。一個Replica Set只能有一個Primary節點,當Primary掛掉后,其他Secondary或者Arbiter節點會重新選舉出來一個主節點。默認讀請求也是發到Primary節點處理的,需要轉發到Secondary需要客戶端修改一下連接配置。
副本節點[Secondary]
與主節點保持同樣的數據集。當主節點掛掉的時候,參與選主。
仲裁者[Arbiter]
不保有數據,不參與選主,只進行選主投票。使用Arbiter可以減輕數據存儲的硬件需求,Arbiter跑起來幾乎沒什么大的硬件資源需求,但重要的一點是,在生產環境下它和其他數據節點不要部署在同一臺機器上。
注意,一個自動failover的Replica Set節點數必須為奇數,目的是選主投票的時候要有一個大多數才能進行選主決策。
搭建集群
了解了基本概念之后,就開始嘗試搭建集群,為了更好的理解,特意找了三臺測試機進行部署。
前期準備
首先準備三臺測試機:
10.100.1.101 主節點(master)
10.100.1.102 備節點(slave)
10.100.1.103 仲裁點(arbiter)
然后就是mongo的安裝包(由于線上用的是3.4.2的版本,所以保持統一)
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.4.2.tgz
相關推薦
相關下載
熱門閱覽
- 1如何查看Mongodb的版本號(mongodb版本查看)
- 2從0到1實現mongodb增量更新操作(mongodbinc)
- 3優化MongoDB的寫入性能(mongodb寫入優化)
- 4Mongodb解決中文亂碼問題的方法詳解(mongodb中文亂碼)
- 5ongodb架構MongoDB架構:可擴展且高可用的數據庫解決方案(mongodbm)
- 6數據恢復災難:MongoDB 誤刪數據的解決方案(mongodb誤刪)
- 7MongoDB:精確定義字段類型的指南(mongodb字段類型)
- 8MongoDB安裝教程:bin目錄在哪里?(mongodb目錄bin)
- 9結構使用MongoDB查看表結構(mongodb查看表)
- 10Mongodb底層:了解其核心技術原理(mongodb底層)
- 11如何優雅地關閉MongoDB數據庫(mongodb關閉)
- 12使用MongoDB快速讀取大量文件的方法(mongodb讀取文件)
最新排行
- 1Unlocking the power of MongoDB: Managing 100 databases made easy.(mongodb100)
- 2MongoDB數據類型修改方法(mongodb修改類型)
- 3MongoDB大數據處理權威指南(mongodb大數據處理權威指南)
- 4shardingMongoDB自動分片技術:實現高效穩定的數據訪問(mongodbauto)
- 5如何在MongoDB中添加新用戶?(mongodb加用戶)
- 6Mongodb異步: 改善數據讀寫效率的有效方法(mongodb異步)
- 7提高數據管理效率,選擇MongoDB中國(mongodb中國)
- 8MongoDB在數據庫領域的占有率如何?(mongodb用的多嗎)
- 9使用MongoDB通配符進行精確查詢(mongodb通配符)
- 10使用MongoDB和JSP構建高效的Web應用(mongodbjsp)
- 11MongoDB連接配置:輕松入門!(mongodb 連接配置)
- 12從0到1實現mongodb增量更新操作(mongodbinc)

網友評論