PostgreSQL HOT與PHOT有哪些區(qū)別
時(shí)間:2024-02-09 10:40作者:下載吧人氣:15
1、HOT概述
PostgreSQL中,由于其多版本的特性,當(dāng)我們進(jìn)行數(shù)據(jù)更新時(shí),實(shí)際上并不是直接修改元數(shù)據(jù),而是通過新插入一行數(shù)據(jù)來進(jìn)行間接的更新。而當(dāng)表上存在索引時(shí),由于新插入了數(shù)據(jù),那么索引必然也需要同步進(jìn)行更新,這在索引較多的情況下,對(duì)于更新的性能影響必然很大。
為了解決這一問題,pg從8.3版本開始就引入了HOT(Heap Only Tuple)機(jī)制。其原理大致為,當(dāng)更新的不是索引字段時(shí),我們通過將舊元組指向新元組,而原先的索引不變,仍然指向舊元組,但是我們可以通過舊元組作為間接去訪問到新的元組,這樣就不用再去更新索引了。
2、HOT實(shí)現(xiàn)技術(shù)細(xì)節(jié)
要使用HOT進(jìn)行更新,需要滿足兩個(gè)前提:
- 新的元組和舊元組必須在同一個(gè)page中;
- 索引字段不能進(jìn)行更新。
當(dāng)我們進(jìn)行HOT更新時(shí),首先是分別設(shè)置舊元組的t_informask2標(biāo)志位為HEAP_HOT_UPDATED和新元組為HEAP_ONLY_TUPLE。
更新如下圖所示:
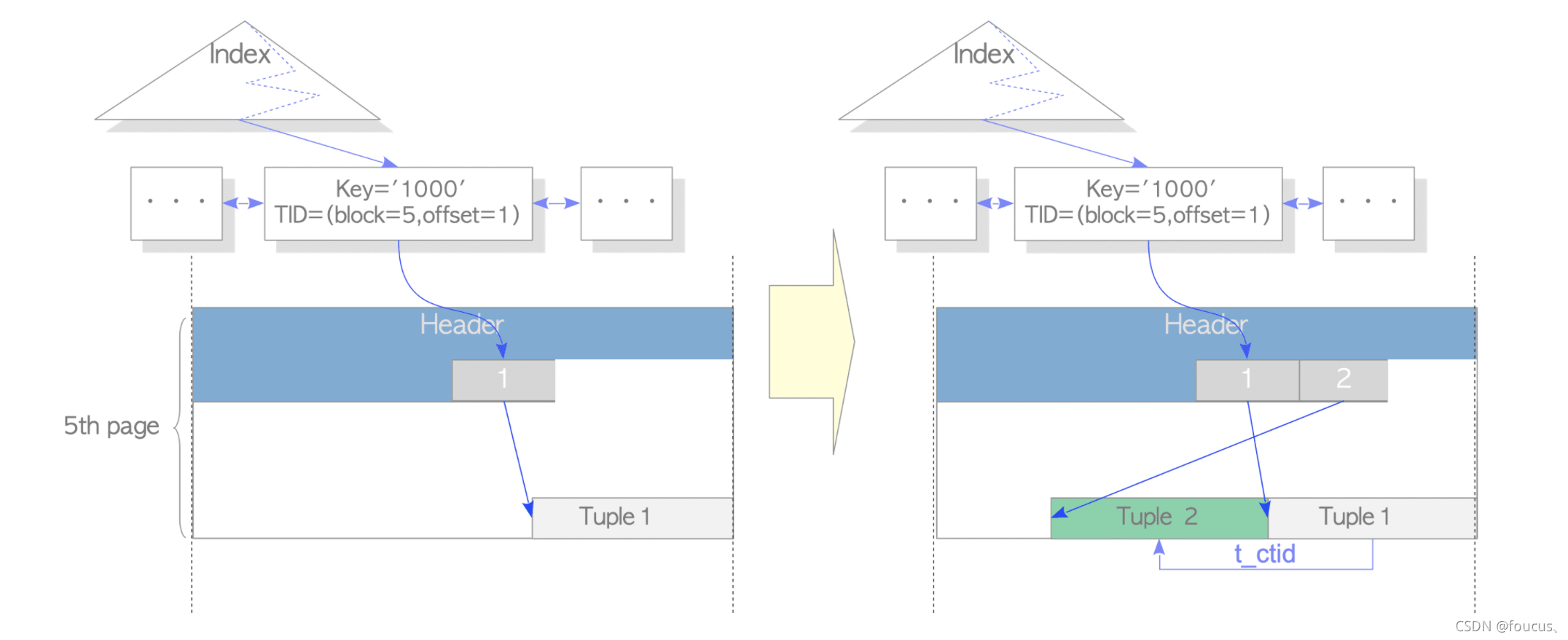
我們更新tuple1為tuple2,分別設(shè)置這兩行元組的t_informask2標(biāo)志位,然后tuple1的ctid指向tuple2,而tuple2指向自己。
但是這樣存在一個(gè)明顯的問題,我們都知道pg會(huì)定期進(jìn)行vacuum清理那些死元組,那么我們這里如果通過tuple1去訪問tuple2的話,tuple1這個(gè)死元組被清理了又該怎么辦呢?
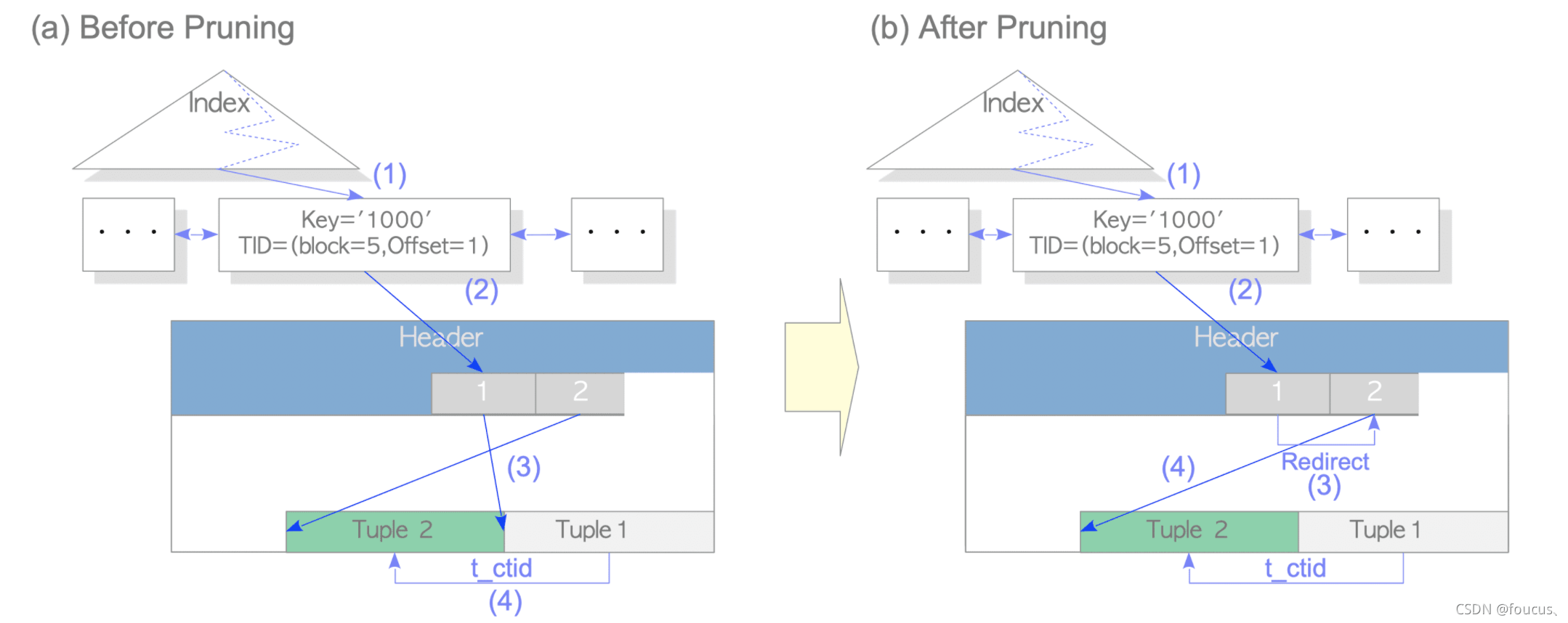
所以pg會(huì)在合適的時(shí)機(jī)進(jìn)行行指針的重定向,將舊元組的行指針指向新元組的行指針,這一過程稱為修剪。于是在修剪之后,我們通過HOT機(jī)制訪問數(shù)據(jù)便成了這樣:
1、通過索引元組找到舊元組的行指針1;
2、通過重定向的行指針1找到行指針2;
3、通過行指針2找到新元組tuple2。
這樣即使舊元組tuple1被清理掉也沒有影響了。
HOT對(duì)應(yīng)的wal日志實(shí)現(xiàn):
對(duì)于HOT的update操作,其wal日志中記錄的信息主要是由xl_heap_update結(jié)構(gòu)存儲(chǔ)。
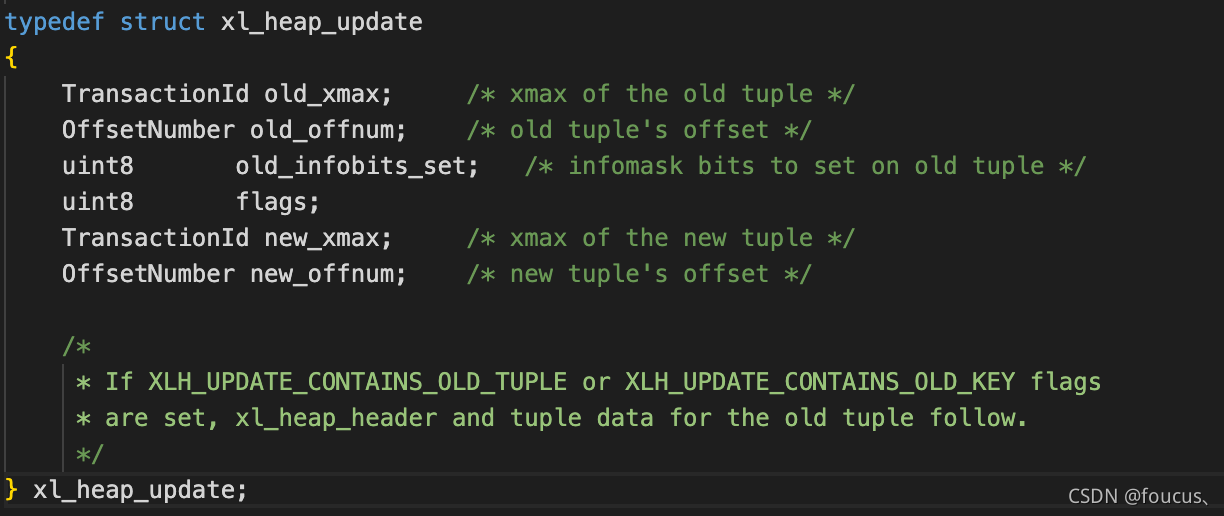
如果新的元組存儲(chǔ)在 block_id 為 0 的塊上,如果不是 XLOG_HEAP_HOT_UPDATE,那么舊的元組將會(huì)存儲(chǔ)在 block_id 為 1 的塊上。反之如果block_id 為 1 的塊沒有被使用,那么則認(rèn)為是 XLOG_HEAP_HOT_UPDATE。
3、何時(shí)進(jìn)行修剪
前面我們提到了,舊行的行指針會(huì)重定向到新行的行指針,這一過程稱之為修剪。那么什么時(shí)候會(huì)發(fā)生修剪呢?
一般來說,當(dāng)我們執(zhí)行select、update、insert、delete這些命令時(shí)均有可能觸發(fā)修剪,其觸發(fā)機(jī)制大致有兩種情況:
- 上一次進(jìn)行update時(shí)無法在本page找到足夠的空間;
- 當(dāng)前page上剩余空間小于fill-factor的值,最多小于10%

除此之外,當(dāng)進(jìn)行修剪時(shí),還會(huì)選擇合適的時(shí)機(jī)進(jìn)行死元組的清理,這一操作稱為碎片整理。碎片整理發(fā)生在當(dāng)我們對(duì)元組進(jìn)行檢索時(shí)發(fā)現(xiàn)空閑空間少于10%時(shí),和修剪不同的是,碎片整理不會(huì)發(fā)生在insert時(shí),因?yàn)樵摬僮鞑⒉粫?huì)檢索行。
相較于普通的vacuum操作,碎片清理并不涉及索引元組的清理,開銷相對(duì)于常規(guī)的清理要小很多,是通過PageRepairFragmentation函數(shù)來實(shí)現(xiàn)的。
這也是為什么HOT要求新舊元組需要在同一個(gè)page中,雖然從理論上來說我們可以將行指針的鏈表指向不同page,但是這樣我們便不能使用page-local的操作來進(jìn)行碎片清理了。
4、HOT的不足
前面我們提到了HOT的前提條件之一就是:更新的列不能是索引列。需要注意,當(dāng)更新的列是索引列時(shí)并不僅僅是會(huì)修改該列上的索引,整張表上所有的索引均會(huì)被修改。
例子:
創(chuàng)建測(cè)試表:
bill=# create table a(id int, c1 int, c2 int, c3 int);CREATE TABLE
bill=# insert into a select generate_series(1,10), random()*100, random()*100, random()*100;
INSERT 0 10
bill=# create index idx_a_1 on a (id);
CREATE INDEX
bill=# create index idx_a_2 on a (c1);
CREATE INDEX
bill=# create index idx_a_3 on a (c2);
CREATE INDEX
相關(guān)推薦
- PostgreSQL vs. MySQL: 數(shù)據(jù)庫對(duì)比(postgresql和mysql)
- Postgresql數(shù)據(jù)庫實(shí)現(xiàn)事務(wù)回滾技術(shù)(postgresql回滾)
- 解決sqoop從postgresql拉數(shù)據(jù),報(bào)錯(cuò)TCP/IP連接的問題
- 實(shí)現(xiàn)高可用:postgresql的主從復(fù)制原理和配置方法(postgresql主從)
- Postgresql:開啟你的數(shù)據(jù)之旅(進(jìn)入postgresql)
- ?探究PostgreSQL:一款強(qiáng)大的數(shù)據(jù)庫系統(tǒng)(postgresql是什么)
- PostgreSQL去掉表中所有不可見字符的操作
- 輕松搞定:postgresql數(shù)據(jù)庫的安裝教程(安裝postgresql)
- 權(quán)限管理PostgreSQL訪問權(quán)限安全控制管理(postgresql訪問)
- Postgresql 檢查數(shù)據(jù)庫主從復(fù)制進(jìn)度的操作
相關(guān)下載
熱門閱覽
- 1PostgreSQL:優(yōu)勢(shì)與不足(postgresql優(yōu)缺點(diǎn))
- 2PostgreSQL DBA 面試寶典 面試題 52道(含10大常見題)
- 3『PostgreSQL:強(qiáng)大而友好的數(shù)據(jù)庫』(postgresql特點(diǎn))
- 4PostgreSQL 默認(rèn)權(quán)限查看方式
- 5解決postgresql軟件卸載問題(postgresql卸載)
- 6詳解PostgreSql 的 table和磁盤文件的映射關(guān)系
- 7Debian中PostgreSQL數(shù)據(jù)庫安裝配置實(shí)例
- 8在Ubuntu中安裝Postgresql數(shù)據(jù)庫的步驟詳解
- 9Postgresql在mybatis中報(bào)錯(cuò):操作符不存在:character varying == unknown的問題
- 10PostgreSQL 數(shù)據(jù)庫基礎(chǔ) 如何查看表的主外鍵等約束關(guān)系詳解
- 11sqoop讀取postgresql數(shù)據(jù)庫表格導(dǎo)入到hdfs中的實(shí)現(xiàn)
- 12postgresql 數(shù)據(jù)庫 查詢集合結(jié)果如何用逗號(hào)分隔返回字符串處理的操作
最新排行
- 1PostgreSQL vs. MySQL: 數(shù)據(jù)庫對(duì)比(postgresql和mysql)
- 2Postgresql數(shù)據(jù)庫實(shí)現(xiàn)事務(wù)回滾技術(shù)(postgresql回滾)
- 3解決sqoop從postgresql拉數(shù)據(jù),報(bào)錯(cuò)TCP/IP連接的問題
- 4實(shí)現(xiàn)高可用:postgresql的主從復(fù)制原理和配置方法(postgresql主從)
- 5Postgresql:開啟你的數(shù)據(jù)之旅(進(jìn)入postgresql)
- 6?探究PostgreSQL:一款強(qiáng)大的數(shù)據(jù)庫系統(tǒng)(postgresql是什么)
- 7PostgreSQL去掉表中所有不可見字符的操作
- 8輕松搞定:postgresql數(shù)據(jù)庫的安裝教程(安裝postgresql)
- 9權(quán)限管理PostgreSQL訪問權(quán)限安全控制管理(postgresql訪問)
- 10Postgresql 檢查數(shù)據(jù)庫主從復(fù)制進(jìn)度的操作
- 11數(shù)據(jù)庫PostgreSQL:開放源碼的分布式數(shù)據(jù)庫管理系統(tǒng)(postgresql開源)
- 12用戶PostgreSQL的新用戶:創(chuàng)建步驟(postgresql新建)

網(wǎng)友評(píng)論